CWRC Ontology Preamble
Abstract
The Ontology of the Canadian Writing Research Collaboratory (cwrc.ca) brings together various linked data materials produced within the Collaboratory related to the writers, writing, and culture.
1. Introduction
Although it contains quite general components for activities such as annotation and citation, the focus of the CWRC ontology is on describing and relating aspects of literary studies and literary history, with a strong emphasis on gender and intersectional analysis indebted to its roots in The Orlando Project, a history of women’s writing in the British Isles. It links to a number of standards while attempting to indicate the complexity of the relationship between representation and provenance in the production of linked data, and to convey the situatedness (Haraway, 1988) of the knowledge that it represents.
Some of the materials associated with this ontology are produced by activities conducted within the Collaboratory. Others are produced through a process of translation from embedded XML markup. In other words, some are the product of human creation or curation, and others are machine-generated.
2. About this Document
This document is a human-readable version of the ontology that cannot document all of its data structures. The ontology itself should be the primary source for understanding how the ontology works.
The intended audience of this document is the scholar that wishes to understand how the ontology tackles concrete data recording problems and the linked open data practitioner that intends to make use of this ontology.
3. Status of this dynamic ontology
This document and the associated ontology will grow iteratively with modifications made over time as data is progressively translated and further ontological concerns are identified. Continuity is ensured using the OWL ontology annotations for ontological compatibility and for deprecated classes and properties. Deprecated ontology terms remain present but are marked as such.
The ontology is understood to be a living document that makes no claims to completeness. Instances have been derived from particular datasets and will be expanded progressively over time.
We welcome suggestions for new classes, properties, and predicates from those wishing to use the ontology for their own datasets, as well as suggestions related to the complexity of vocabularies associated with existing terms. Please submit suggestions via an issue or a pull request to the CWRC Ontology code repository.
4. Background on the Orlando source data
In 1995, the Orlando Project embarked on a history of women’s writing in the British Isles from the beginnings to the present (Brown, Clements and Grundy, 2007a;Brown, Clements and Grundy, 2007b).
This born-digital collaboration devised a knowledge representation (Brown, Clements et al., 2006) in the form of a bespoke SGML tagset to encode the project’s intellectual priorities and concepts in the text as it was being written. This tagset structures the biocritical, chronological, and bibliographical content of the resulting history of more than 8 million words and 2 million tags. The schema provides the basis of that of the Canadian Writing Research Collaboratory for similar content, and provides the foundation of this ontology. Some of the source data is produced via extraction from XML tags embedded in Orlando Project materials and the similarly structured content within the Collaboratory (Simpson and Brown, 2013).
Orlando: Women’s Writing in the British Isles from the Beginnings to the Present (Brown and Clements and et al., 2006) is published by Cambridge University Press.
The scholarly introduction and introduction to the Orlando tagset are available here: Introduction to Orlando Tagset.
Contributors to Orlando are listed here: Orlando Project Contributors.
The Orlando Project’s XML schemas and the CWRC Project’s XML schema are available on Github.
5. Basic ontological goals
a. Principles
The schema covers entities, classes, and relationships associated with the domains of literature and literary and cultural history as understood from an intersectional feminist perspective. The ontology design responds to the challenges of shifting from semi-structured to structured data (Smith, 2013). Although linked data triples stand on their own formally, many are derived from discursive prose and are best read in an environment that links back to their original context. The CWRC ontology design avoids representing RDF extractions from Orlando data as positivist assertions, and yet produces machine-readable OWL/RDF-compliant graph structures. It allows references to, without endorsing, external ontological vocabularies that are nevertheless part of documenting cultural processes and identities.
b. Competency Questions
Competency questions are meant to provide a sense of scope to an ontology. These can serve a number of purposes including giving users a sense of what kind of information they might find in datasets that employ the ontology, and giving the ontology developers criteria against which to measure the success of the ontology. The CWRC ontology represents a wide range of information about writers’ lives, literary careers, and literary works. Moreover, as with other humanities data, this information may be put to a wide range of uses, many of which will not be foreseeable. For instance, the nineteenth-century novels of Susanna Moodie have been searched for evidence of specific weather events by researchers into climate change. This list will therefore not be exhaustive, but it should give some sense of the range of questions we would expect the ontology to be able to address. The fact that the datasets represented by this ontology cannot be comprehensive also needs to be stressed: the unevenness of the archival and published record, in addition to the necessarily selective and variously prioritized ways in which the information has been collected and recorded, mean that any sense of statistical significance or representativeness related to the kind of data for which this ontology is designed must be highly qualified and contextualized.
Biography-based questions
- What people are known to have attended school in a certain city over a particular period of time?
- What British authors attended the same schools as each other?
- What writers were taught by or schooled alongside another woman writer?
- Who is recorded to have died from a particular cause of death in a particular time period?
- What family members is a particular person recorded to have had, and how were they related?
- Which queer/lesbian identified authors are recorded as having attended single-sex institutions?
Cultural Formation
- What people were identified with a particular race, colour, or nationality?
- What women during the Victorian period were associated with multiple nationalities?
- What writers had some form of Jewishness in common?
- What British writers were associated with both Protestantism and Catholicism in the nineteenth century?
- What literary texts engage with a particular religion or denomination?
- What is the breakdown by the different genders represented in this dataset of novels published during a particular period?
- Which writers are associated with a particular political affiliation?
- Are writers more likely to be associated with gender-related causes at particular points in history?
Human Relationships
- Does a connection exist between two particular people?
- How close is the connection? Is it asserted frequently in the data, as opposed to occurring only once or twice?
- What types of connections to other people does a particular person have?
- What family ties does this person have?
- If two people are not connected, what is the shortest path between them via relationships with other people, or with other entities such as organizations or texts?
- What connections exist between a set of people during a specified period in time?
- How many people cite a particular author as influential in their own work?
- How many writers are related to a particular organization? More specifically, which feminist organizations were supported by two or more generations of writers from a single family?
- Who are all the people noted here with whom this author collaborated professionally (editor to writer relationships; author to author; editor to editor, etc.)?
- Who had a relative involved in professional publishing spheres?
Clustering/Networking People
- What authors are most interconnected with other authors in terms of their influence?
- Can we identify clusters of writers who seem to be operating as a community in terms of having a tight network of friendships, literary relationships, use of the same publishers, reviewing each other’s works, etc.?
- Can we identify individuals who were key connections between different groups?
- Whose work was influenced by British and/or international writers of colour?
- Who was involved in both feminist groups and animal welfare activism?
- Who was in touch with non-literary artistic groups?
Texts/Works based questions
- What books were important to this author’s education?
- What reviews exist for a particular book?
- In what languages has a particular work been published?
- Is there any acknowledged intertextual relation between X and Y?
- In which journals does a particular author’s work appear?
- How many intertextual relationships does an author have to female-authored literary works?
- Find all the responses to this book that are deemed to be gendered.
- Which works are represented as the most translated?
- Find particular themes and topics in texts, such as which works of the imagination contain depictions of women’s colleges? Which depict political organizations?
- Which authors wrote for the same journal and in the same time period?
- Which fictional works allude to a particular type of activism?
- Are there references to fictional works in this author’s non-fictional work?
- Which European fictional texts are set outside of Europe?
- Who destroyed her own works? Whose works were destroyed by others?
- Which works seem to have been influenced by certain theorists or philosophers?
Geography based questions
- Which texts were or were not published in a particular country?
- Which texts were or were not reviewed in a particular country?
- In which cities or nations did a particular author reside?
- Which cities or nations are depicted or discussed in an author’s work?
- In what locations has a particular play been performed over time?
- Which works were written during travels?
- Which texts were published or otherwise shared in countries outside of Europe? Which texts were reviewed in countries outside of Europe?
Time- (and Event-) Related Questions
- What are the most discussed texts of a particular temporal period within this dataset?
- Trace the impact of a particular text through time and space.
- What is the relative rise or fall of a writer’s reputation over time, in relation to other writers in the period?
- What events in this person’s life were related to aspects of social identity such as religion, social class, or political affiliation?
- What changes over time are recorded in the frequency of the kinds of relationships that the data describes, across numerous writers? E.g. Does this dataset record greater degrees of intertextuality with male writers or female writers, relatively speaking, at different points in time?
- What major social or historical events and developments are reflected in the literary record?
- Can we target exploration of the data at particular temporal periods, such as the Victorian period?
- Which authors are likely to have known each other, due to overlapping chronologies, locations, and other connections in common?
Complex questions
In many cases the ontology will play a part in investigating a more complex question or as a component of a larger hermeneutical process. For instance:
- Let me compare the publication patterns of writers, distinguishing by gender and by the number of children that they had. Looking at it over time, does their rate of literary productivity increase or decrease in relation to the number of children they have?
- Show all the elements of both self-taught and formal education (books, subjects, instructors) that are also alluded to in a writer’s works.
- Trace the impact of developments in writing, such as the emergence of a particular theme or formal feature, to a larger social development.
- Test claims about the rise of genres or literary movements and see how they look when inflected by a dataset focused on women’s writing.
c. Anticipated tools and functionalities
Also relevant to the structure of the ontology are the kinds of tools and functionalities that it aims to support. These are:
- Searches through SPARQL queries;
- Browsing, including faceting according to various criteria based on the ontology, including temporal periods, geographical locations, or the properties of writers;
- Linking to our instance data by way of their URIs;
- Discovery of significant information about instances through dereferenceable web pages;
- Discovery of materials across the web that reference instances or other components of the ontology;
- Graph Visualization of the structure of the ontology, including the properties and relationships it contains;
- Network Visualization of the relationships between people and other people, and influence and relationship graphs showing connections between people and other entities such as books, indicating the directionality of relationships where appropriate.
- Mapping of components of the data associated with geospatial information;
- Timelines of components of the data associated with temporal information;
- Use of SHACL rules and other logical inferencing tools to check for data errors, omissions, and consistencies;
- Use of SHACL rules and other inferencing tools to derive new information from the combination of existing data and the ontologies;
- Expose the unevenness of datasets by enabling the tracking of sources, provenance, and degrees of certainty in order to provide insight into gaps in the knowledge base;
- Expose conflicts, contradictions, and outliers within datasets as a basis for inquiry.
d. Linkages to external ontologies
We employ a number of strategies for linking to other ontologies. Our architecture does not typically import other ontologies wholesale, but relates to large vocabularies in defined ways. We try not to abuse sameAs predicates (Halpin, Hayes et al., 2010).
We adopt external namespaces and associated classes and terms wherever possible when they are in widespread use and their vocabularies are broadly compatible with ours, as in the case of the FOAF and BIBO vocabularies. For some terms, such as those for religious denominations or genres, we are happy to draw on other vocabularies’ terms and definitions in part or in whole, as in the case of terms from the Getty Art and Architecture Thesaurus (Getty Research Institute). Other terms are referenced, but usually at a distance rather than through wholesale import. This is particularly common in relation to cultural forms, which, as explained more fully below, are understood primarily as representational and linked, where multiple related terms exist within the ontology, to terms typed as textual labels. By means of this structure, our vocabulary positions all terms associated with processes of Cultural Form as discursive labels, retaining the ambiguity of terms implicated in the complex social construction of identities within a narrative. Cultural forms may in turn be related to external ontologies in a number of ways. If an external ontology term aligns semantically with ours, then we use OWL- or SKOS-based relationships such as <owl:equivalentClass>, <skos:narrower> or <skos:broader>. If an external term's definition or use is not commensurate with a term in the CWRC ontology but its application in external datasets is such that it will be useful nevertheless to link those terms to ours (for instance for broadening searches using the problematic ISO5218 Codes for the representation of human sexes), then the has functional relation predicate is employed to indicate that the relationship is specified semantically but may be leveraged for processing.
At the top level, the CWRC ontology makes use of the following well known ontologies:
- The FOAF ontology for the representation of people and organizations.
- The BIBO ontology for the representation of bibliographic data.
- The TIME ontology for the representation of events and points in time where ISO8601/XML Schema times are not appropriate.
- The Web Open Annotation data model is used to link the original Orlando text to specific Contexts.
- The SKOS vocabulary is used to represent taxonomical relationships within certain Cultural Forms and to fully document ontology terms.
- Some Dublin Core vocabulary terms are used for well known documentation tags such as
<dcterms:title>. - The W3C Provenance ontology is used to indicate indebtedness, derivation or provenance of term descriptions as well as Cultural Context source annotations.
- Linkages are made to the CIDOC-CRM ontology to cultural instances that are in common with CWRC.
Established ontologies and vocabularies are used in the definition of numerous classes and instances. For instance, the religious terms of the Getty Art and Architecture Thesaurus provide suitable definitions for many religions, as does DBPedia for many terms throughout the ontology. Sometimes definitions draw on scholarly print and online sources. Quotation marks around the text of the description indicate wholesale adoption of the source definition. Where the description is not surrounded by quotation marks, the term has been defined by the CWRC team, but links may be provided to external resources such as a scholarly article or closely related DBpedia entry.
In other cases, terms from external ontologies are adopted in CWRC datasets without having been imported into our ontology. What follows is a non-exhaustive list of such vocabularies and the classes for which they are most frequently used:
- Geonames terms are often used for locations and for many instances of geographic heritage.
- Library of Congress Languages codes are typically used for instances of language.
e. Provenance and contexts
As noted above, some data associated with this ontology has been generated from XML structures (Simpson and Brown, 2013). Provenance is thus particularly important, given that such data was not originally produced in RDF but rather in the form of tags embedded in a discursive context. In such cases, the relevant portions of the text are provided in the form of snippets, which within the dataset become instances of contextual notes or human-readable annotations to which the dataset nodes are directly tied.
The wholesale import of entire vocabularies within the CWRC ontology was likely to cause logical and ontological problems. To this end, we opted not to use the <owl:import> construct and instead either to link to vocabularies externally or to clone specific sets of terms from selected vocabularies. Similarly, not all vocabularies are well-defined from an ontological standpoint, but drawing from their narrative or some of their properties proved useful. To this end, we avoided the use of <owl:sameAs> so as not to bring unintended properties or ontological structures into the CWRC ontology. In other cases, the Provenance ontology property <prov:wasDerivedFrom> is used to indicate that the term was constructed using information from other terms without necessarily being equivalent. Direct linkages to other ontologies are usually made through the use of subClasses or <owl:equivalentClass>.
f. Labels
For labelling, CWRC utilizes two means of promoting searchability. rdfs:label represents the human-readable nomenclature for a concept, instance, or predicate. This is the terminology used when representing components of the ontology in documentation and diagrams, except where a URI is provided.
As noted above in relation to cultural form, however, when textual label is used to type a class, this is an indication of the representationality or discursivity of that class. cwrc:TextLabels are frequently used for ambivalent, overlapping, and culturally contested terms.
In addition, to support those with knowledge of prior datasets whose strings or terms have been linked for extraction purposes to CWRC terms, the ontology provides additional linguistic context for CWRC ontology terms. Alternative labels, signified by skos:altLabel, indicate terms from source datasets that have been employed to create relationships to this concept. Alt labels typically cannot serve as replacements for rdfs:label. Within the ontology, such alternative labels primarily exist for search and retrieval by allowing ontology terms to be located under a larger number of labels. Although some reflect the idiosyncrasies of the source data, they may be useful for broadening searches.
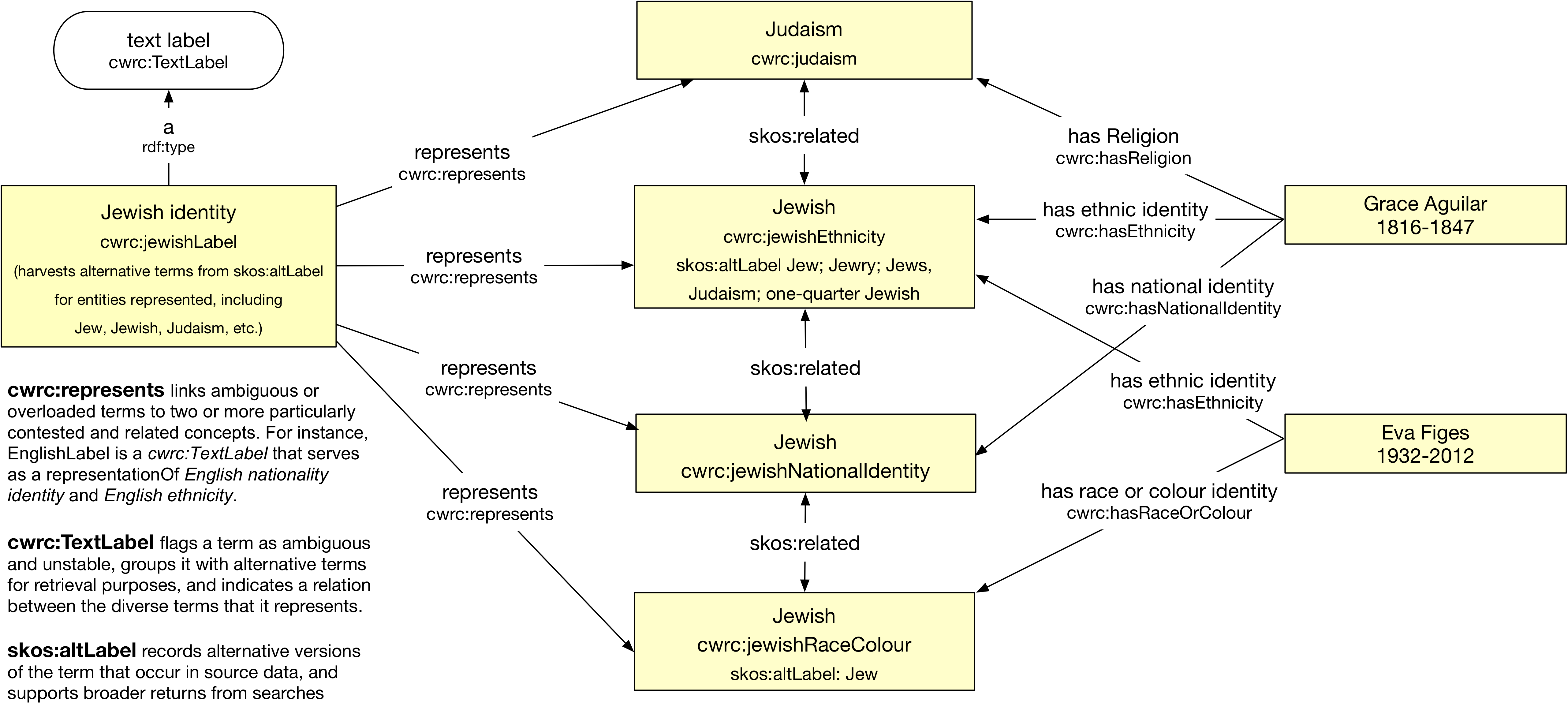
g. Cultural diversity
Cultural diversity has been an increasing source of debate beyond and within the digital humanities community. The concentration within the Debates in Digital Humanities series (Gold, 2012; Gold and Klein, 2016) of pieces reflecting the increasing prominence of matters related to race, gender, cultural diversity, and difference is but one marker of the extent to which diversity matters. This ontology seeks to convey an intersectional understanding of identity categories, as instantiated in The Orlando Project’s XML Biography schema.
The Cultural Form portion of the ontology recognizes categorization as endemic to social experience, while incorporating variation in terminology and the contextualization of identity categories. It understands social classification as culturally produced, intersecting, and discursively embedded. We invoke categories as the grounds for cultural investigation rather than fixed classifications, since such categories have never been stable or mutually exclusive (Algee-Hewitt, Porter, and Walser, 2016). For a more detailed explication of cultural formation, see Brown et al 2017.
6. CWRC ontological structures
Source data from CWRC spans multiple types of data, including granular material such as bibliographic metadata and discursive, interpretive, or analytical content. The CWRC linked open dataset represents such information as a series of assertions, frequently associated with particular contexts.
While full, integrated traceability has always been a core need of repeatable experiments, this comes at a complexity cost within a linked open dataset in that the queries required to retrieve basic information become unwieldy. To this end, the CWRC ontology records information through a design that supports the tracking of provenance, certainty, and other complex components of the data, but is easily queried to produce simple triples. This design relies heavily upon and extends the Web Annotation Data model. Web Annotation supports quite standard forms of annotation, such as identifying entities named in a text or providing a keyword or correction, connecting the entities to the associated source in a way that supports provenance.
CWRC also builds on the Web Annotation structure to carry properties associated with those entities through a series of Contexts, typed according to a number of high-level classes such as EducationContext, CulturalFormContext, and OccupationContext.The properties associated with entities for each Context have parallel subject-centric versions, that support the use of SPARQL Construct commands to derive entity-centric triples that simply link individuals to their personal attributes. In this way, deep provenance tracking is enabled while the production of granular subject-predicate-objects views of the data is supported by the ontology structure. Contexts thus link a fragment of source text to the individuals or entities whom it references, the properties or assertions situated within that context, and the class of experience or activity to which it belongs.
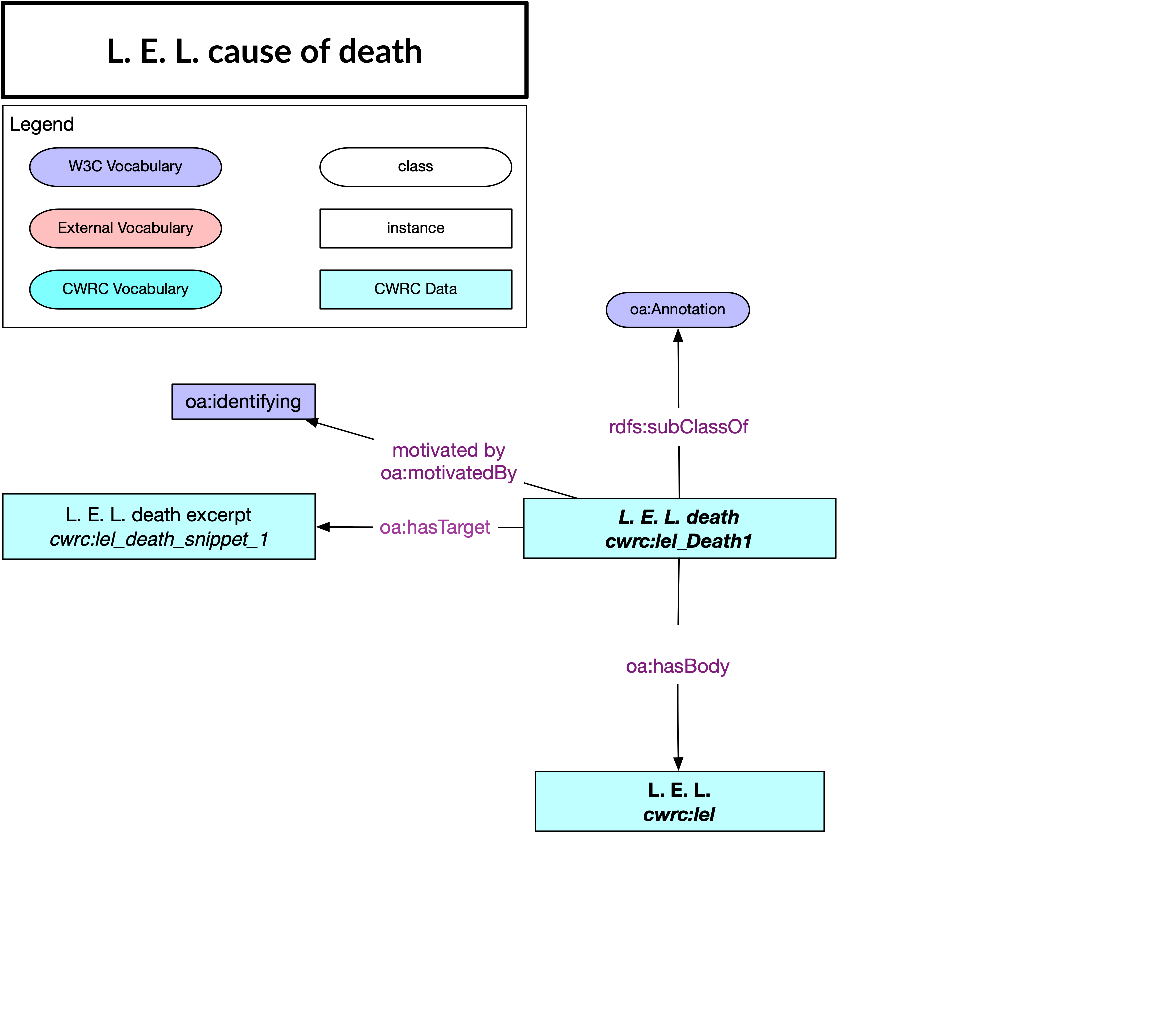
a. Identifying Annotations
Much CWRC linked data will involve the identification of named entities within CWRC documents, which is a straight-forward use-case for Web Annotation. Here below is a diagram of a Web Annotation identifying the person entity L.E.L. (Letitia Elizabeth Landon) within an excerpt or snippet from the Orlando Project’s published textbase.
b. Contexts (Describing Annotations)
The Context class uses Web Annotations to provide the discursive context for interpretive assertions in the ontology. Where the assertions have been generated from a web-accessible source text, a Context provides the text, or the relevant snippet of a longer text, from which they have been extracted. Contexts help to ground the data in its source materials, which can provide users with a sense of the nuance and complexity of assertions related to human subjects and cultural phenomena.
Contexts are typed by major semantic categories including, for biographical material, Cultural Forms, Birth, Death, Education, Occupation, and Politics, and, for literary content, Production, Reception, and Textual Features.
The major context classes are as follows:
BiographyContext, BirthContext, CulturalFormContext, DeathContext, EconomicContext, EducationContext, FamilyContext, FriendsAndAssociatesContext, HealthContext, IntimateRelationshipContext, LeisureContext, NameContext, OccupationContext, SpatialContext, and ViolenceContext.
CWRC Contexts build on the Web Annotation structure, classing Annotations by Context. While identifying annotations are used to indicate the presence of particular entities, we shift the motivation of the annotation to describing when it comes to properties such as cause of death, since these annotations are describing what Orlando is saying, as well as engaging in description themselves.
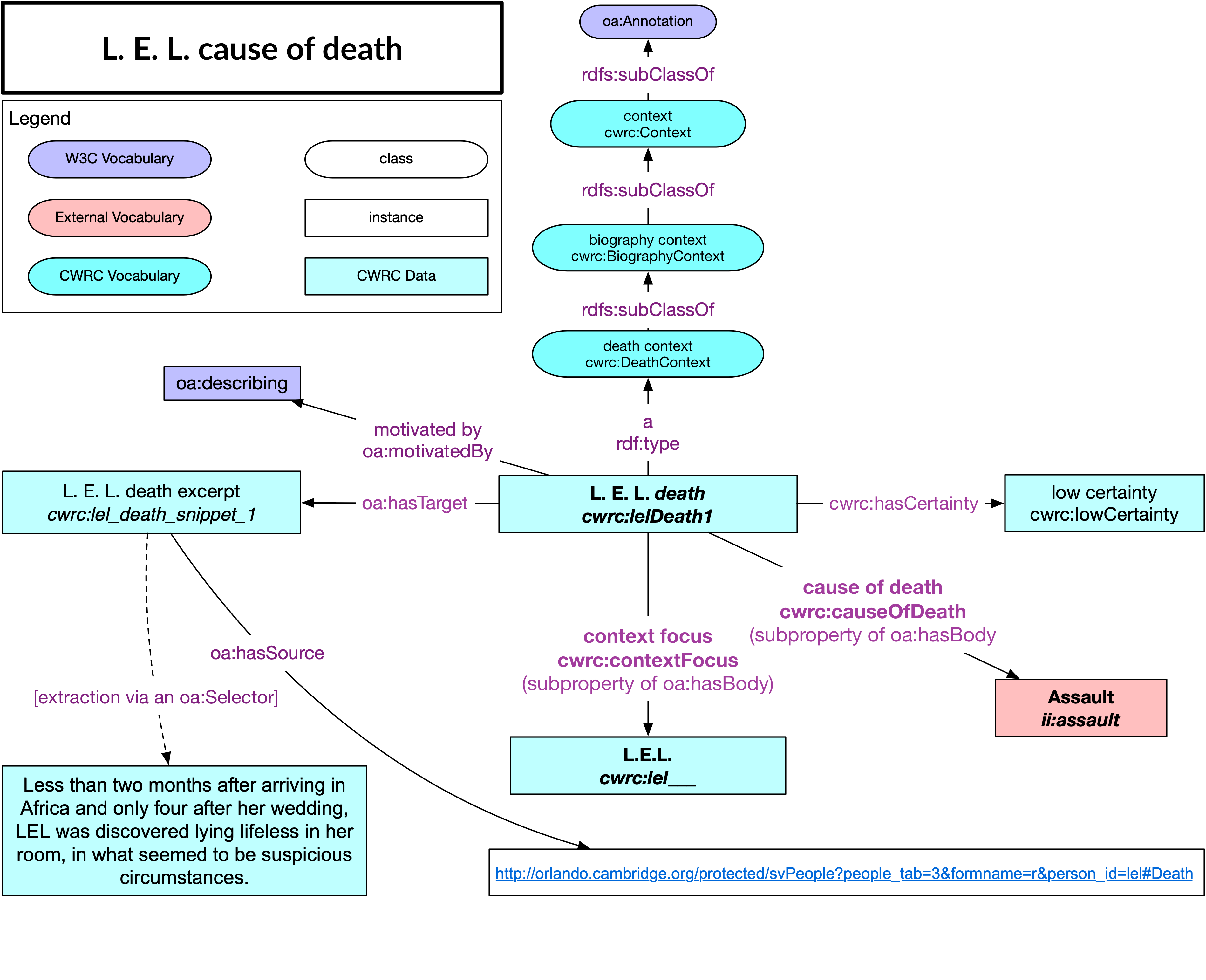
The relationship between L.E.L. and her cause of death is present here, but in a “Context-centric” rather than a subject-centric way. What we think of intuitively as the “Subject” of the cause of death triple, that is L.E.L., is present but is structurally an object: L.E.L, however, has a special, CWRC-defined relationship to the Annotation as the “contextFocus”, which is to say the subject of this particular Context. The “contextFocus” property, like other CWRC-defined properties linked to the annotations, becomes a subproperty of the standard oa:hasBody property. Links to source documents from which the RDF was extracted are there, as is certainty, citation links (not shown here), and potentially other information about this complex assertion. This graph is not as intuitively human-readable, but allows us to retain key contextualizing information that we consider key to creating robust humanities LODsets.
The Context-centric model allows for subject-centric triples, but these would need to be generated from the source data through SPARQL Construct queries. The CWRC Ontology provides both context-centric and subject-centric versions of predicates (for instance, causeOfDeath and hasCauseOfDeath, respectively), so that this can be done as a batch script to create a derivative dataset for those who want to see more direct relationships, or through the SPARQL Construct commands when running queries.
Moreover, the relationship between two different contextualized assertions provides a means of dealing with contradictory data through an OR relation that allows both Contexts to exist even though two assertions associated with them cannot logically both be true – as is the case with L.E.L. whose cause of death is asserted to be both murder or suicide in the source document. In such a case, a low certainty value could be generated based on this contradiction in the data. This model thus provides support for reasoning that will help to identify inaccuracies in the data. It will also help to highlight areas of controversy, edge cases, differences across datasets, and cases of negation or contradiction, not as noise or dirt to be weeded out of the data, but rather as things that humanities scholars frequently want to zero in on and examine more closely.
c. Persons, Personas and Roles
The distinction between persons, personas, and roles is an important component of the complexity of human experiences and relationships.
This ontology adopts the broad FOAF definition of a foaf:person, which can be applied to any entity considered to be a person, including non-humans. We define two subclasses of Person: a NaturalPerson or human being, and a FictionalPerson, since fictional characters are important to literary studies. If a historical person who is a NaturalPerson is fictionalized as a Character [not yet created] in a text, they also become a FictionalPerson. If a text simply alludes or refers to a NaturalPerson, however, they are not also a FictionalPerson.
In some cases, a Person will be associated with a Persona. A person can occupy a Role [not yet created] in relation to a specific event or situation.
The author Michael Field offers an example of the extent to which "personhood is both a complex and a crucial characteristic that ontologies must be designed to capture appropriately" (Brown and Simpson 2013). The persona of Michael Field was produced by the artistic and lived collaboration between Katherine Harris Bradley and Edith Emma Cooper at the turn of the twentieth century. Even though he was not a biological person, Michael Field had an important role in the two women’s careers, their social lives, and their personal relationship. "Michael Field" can neither be assigned to one of the authors over the other, nor can it be considered only a shared pseudonym. Michael Field is associated with two natural persons at the same time. We seek in the CWRC ontology to capture such manifestations of the originality and the plurality of personhood. The ontology thus includes the "persona" class of person to describe entities such as Michael Field.
It might be argued that such personae are simply pen-names or stage names, such as "Currer Bell" for Charlotte Brontë. However, personae are more than alternative signatures. Personae inflect the ways in which artists socially, symbolically, intimately or artistically embody authorship. While a pen-name can be described as a publication strategy related to a specific context, a persona has its own performed personality that goes beyond a signature. A contemporary example is the FASTWÜRMS art collective. The collective operates as more than a creative identity, to the point of holding a single academic position at the University of Guelph.
A particular persona is an original creation, often bearing meaning related to the biographical, historical and sociological context of its creator. A persona in this sense is also not generally associated with mental illness or multiple personality disorders that result from distorted or uncontrolled perceptions of reality. At the heart of a persona is an identity with which others interact and that can be confused with a Natural Person. It is incarnated and developed by a natural person, may have specific properties such as gender or sexuality that differ from those of the natural person with whom it is associated, and may engage in social, literary, artistic or political activities. Although Personae are FOAF Persons, they are distinct from the CWRC Natural Persons who embody them and from Fictional Persons, unless they become fictionalized by themselves or others.
As documented for the recent Persona tag incorporated in the Text Encoding Initiative Guidelines, personae are not Roles either: "A role may be assumed by different people on different occasions, whereas a persona is unique to a particular person, even though it may resemble others. Similarly, when an actor takes on or enacts the role of a historical person, they do not thereby acquire a new persona." (http://www.tei-c.org/release/doc/tei-p5-doc/en/html/ND.html#NDPERSE).
A Role can be adopted by either personae or natural persons, but a persona cannot be adopted by people generally: it is specific to one natural person, or more rarely several natural persons (as in the case of the collaborative Field and the artistic collective FASTWÜRMS art collective).
Roles are characters or functions performed in specific occasions and situations, which is to say events. Dramatic roles, that is to say #Character in a creative work, are adopted by actors for particular performances. By analogy, social roles are adopted by particular individuals in relation to particular events or occurrences, which may be of brief or long duration. Key roles in relation to events are those of agents, spectators, and commentators. Occupations, jobs, or significant activities are not the same as roles, although they may be related to them, as may familial or social relationships. Roles will be further fleshed out in relation to the event component of the ontology, which is currently under development.
d. Cultural Form
The CulturalForm classes recognize categorization as endemic to social experience, while incorporating variation in terminology and contextualization of identity categories by employing instances at different discursive levels. A cultural form represents an aspect of lived social subjectivities and/or classification of a person through categories such as race or colour, ethnicity, gender, language, sexuality, politics, or religion. Most of the properties associated with specific Cultural Forms may also have the additional modifiers of reported and self-reported, allowing for the qualification of individual statements.
Cultural Form sub-classes and instances describe the subject positions of individuals through Contexts. Contexts are linked to granular Cultural Form properties that are in turn associated with the person who is the contextFocus of the annotation. This has its roots in the Orlando arrangement of Cultural Form encodings that points users towards a framework for raising and debating complex matters for cultural investigation rather than invoking reified categories.
The shift from embedded semantic markup to a linked open data approach presented the challenge of making this approach compatible with linkages to other ontologies and datasets outside of the Orlando frame of reference. The move from "strings to links" or "strings to things" was in some sense at odds with the former embrace of the ambiguity of strings such as white, black, English, etc.: white and black can represent race or ethnicity, while English can also be invoked as an ethnicity, nationality, or a national heritage. Orlando marks these strings using its Cultural Forms tagset as specific to, for example, the context of race or ethnicity, mandating a similar association, within the linked data representation, with a specific instance of Cultural Form. Thus, there exist Cultural Form instances that point to the discursive construction of white as a race and white as an ethnicity. Lastly, there also exists a white label that can be instantiated as either race or ethnicity, but not both within the same assertion (although multiple assertions are possible).
This is a departure from previous (non-linked open data) controlled vocabularies, in that the appearance of the term or label (in this case "white") does not indicate the specific cultural formation being invoked, the specific instance does. This also means that linkages to other datasets or vocabularies can be made appropriately, since multiple representations of the same label are present within the CWRC ontology. As a last resort, or for data mining purposes, the term is also available as a concept whose actual Cultural Form is undecided amongst the CWRC-defined options. This allows for linkages to an external ontology, such as can be required by text mining, without endorsing the corresponding definition or interpretation of the term. Finally, skos:altLabel properties provide variant terms that indicate the unstructured vocabulary terms or strings that have been translated to these vocabulary instances.
i. Granular Properties
Granular properties provide a simple means of indicating cultural categories as as presumed, perceived, or otherwise assigned to a person according to cultural conventions, or as self-reported by the person themselves. Some of the properties are associations inherited from forebears.
Most properties take noun forms in keeping with conventions for ontologies, but in some cases idiom makes adjectival forms preferable, even though these terms function as nouns, as in the case of the sexual identity celibate.
e. Built-in Taxonomies
i. Religion
The original Orlando data makes religious reporting a challenge in that the original contexts had no differentiation between religious belief, membership in a religious organization, and absence of any religious belief combined with adherence to values or practices.
We use a taxonomy for enumerating the categories associated with this spectrum. The taxonomy in itself is SKOS-based and represents a loose mixture of the shared beliefs and historical offshoots.
The taxonomy attempts to trace in a subjective way the theological and/or historical lineage of the belief system. Like applying the labels to an individual, this is an interpretive process.
{kind=link}
ii. Political Affiliation
Political affiliation categories cover a broad range of political parties, more and less organized movements, and various causes. The instances here involve a strong emphasis on British political matters historically of interest to women and a recognition that movements such as feminism are contested and change with time and location. Some affiliations are linked via SKOS relations, but there are other cross-currents among different groups that cannot be captured here as well as in the contextualized data itself. As for the other components of this ontology, this vocabulary makes no claims to comprehensiveness, having been derived from the Orlando dataset, and is open to expansion as needed.
{kind=link}
iii. Genre
The separate CWRC Genre ontology contains a taxonomy of cultural media, forms, and genres, with a strong emphasis on literary genres, based on a combined OWL and SKOS approach. In order to facilitate the ability both to apply terms to particular cultural productions and enable them to be discussed as concepts, genres are instances within the CWRC Genre ontology, and are related to particular cultural works through the hasgenre property.
Because it is useful for a number of purposes to be able to move between broader genres and more specific ones, the ontology organizes its terms through a combination of OWL classes that provide broad groupings and SKOS taxonomical relations amongst instances. The OWL classes provide the ability to reason from narrower to broader terms, while the SKOS properties provide more limited transitive narrower/broader relationships.
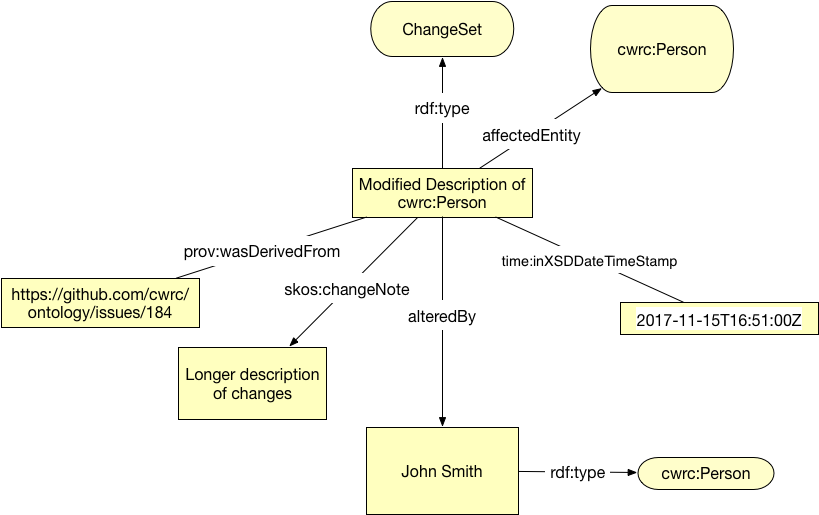
f. Notes on ChangeSets
Change Sets exist to track changes to instances, terms, and classes within the ontology, they are therefore used by both the authors of the ontology as well as users who are making additions or modifications. Change sets are instances that are linked either to or from a structure in the ontology. This is done through the object properties affected entity or through the skos:changeNote. A single change set may apply to several entities therefore the cwrc:affectedEntity relation may be applied 0 or more times. Change sets also track the user through the cwrc:alteredBy relation and may link to any cwrc:NaturalPerson. In addition dates and times are kept track of through time:inXSDDateTimeStamp using xsd:dateStamps to track the instant the change was applied to the ontology. This will allow change sets to be used as release by selecting them between a particular date to show major changes. Through provenance Change Sets may link to external resources allowing extended discussion to be kept out of the ontology. Shorter descriptions are included through the skos:changeNote relation as well as a title using a standard rdfs:label. Change Sets are to be used anytime an issue is completed by ontology developers or an instance is changed by a user. Automated mechanisms will be used to offset some of the work required.
g. Has Functional Relation
The Functional Relation predicate indicates that the two terms may be treated as related for functions such as querying and retrieval, but it also denies a semantic relationship between the two terms. This predicate is designed to bring together incommensurate terms for processing purposes but also to exclude them from semantic operations. This differentiates from, for instance, the skos:semanticRelation property and the skos:closeMatch predicate which serves a similar purpose but asserts a semantic proximity.
One of the purposes for this relation is to facilitate comparisons and relationships to other ontologies and vocabularies with which users are more familiar. Use of this relationship does not assert that the two terms are not related semantically, but rather that the current semantic relationships available within OWL, SKOS, and other ontologies used by this ontology are not sufficiently nuanced to allow for a semantic relationship to be specified in a way that can be processed appropriately by other tools (such as inference engines).
7. CWRC Ontology Design Rules
Beyond the formalism of The OWL 2 Web Ontology Language, the CWRC ontology follows the following design rules and styles:
- The contents of rdfs:labels tags are always in lowercase, with the following exceptions:
- Labels for religions, political affiliations and groups of people derived from a proper name will begin with an uppercase letter.
- Whenever possible, the original Orlando XML tag equivalent is contained within the rdf:value tag of any term within the ontology.
- Whenever referencing a geographical location, use the most precise item within the database.
- Definitions in French, English (and other serendipitously available languages) are never word-for-word translations, and are definitions in their own right.
8. Notes on SKOS and OWL
SKOS (Simple Knowledge Organization System) enjoys widespread popularity in the semantic web community as it provides simple terms for taxonomies without requiring reasoner support. Whenever appropriate, SKOS terms are inserted within this ontology to link terms to each other. However, since these terms are not ontologically powered, their scalability is limited since each additional layer of terms within a taxonomy requires another database query.
Some of the constructs within the CWRC ontology are deep and require reasoning support. OWL is the preferred means of using this ontology, though the usage of the terms, SKOS-style, is possible.
9. Conclusion and Future Work
This is a draft ontology that is very much in progress. It will continue to be developed, expanded, and revised, and potentially broken up into modules, as we discover the implications of how we have structured the ontology through using it to extract and explore our data, and as fresh data and use cases necessitate expansion or refinement, and as new needs, understandings, and debates arise.
10. Version History
0.99 - Initial public release.
0.99.2 - Periodic release with updated logos, genres, documentation, and proper masthead data.
0.99.6 - Periodic release with updated styling, competency questions and documentation regarding events and changesets
0.99.75 - Periodic release
0.99.80 - Periodic release with addition of occupations, educational award types, education credentials